The Kernel Trick in Neural Networks
Experiment
Let's start with a simple cloud of data where the blue points are in a circular disc and the orange points are surrounding the disk
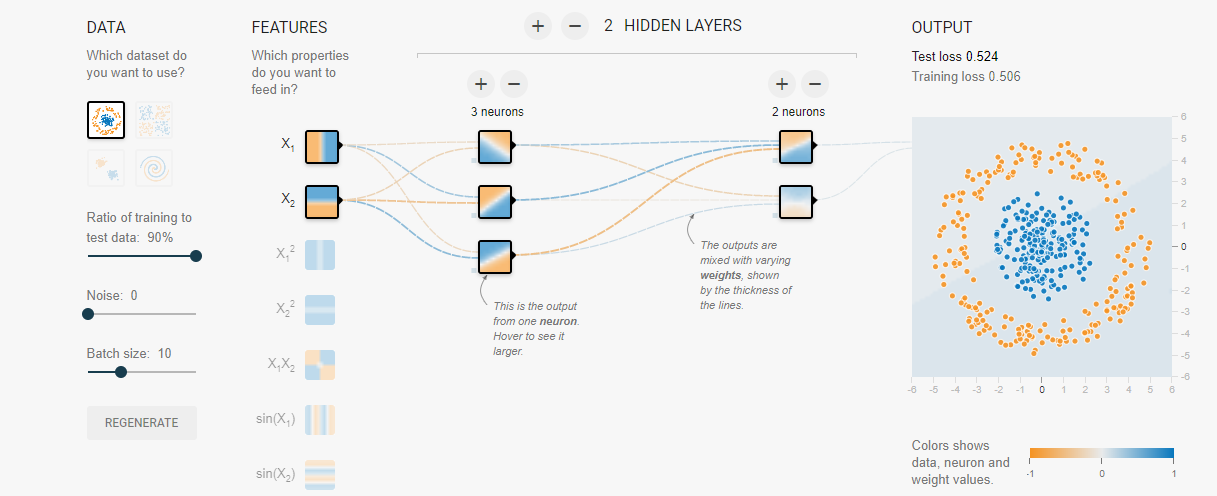
As you can see in the above network, the inputs fed are (x, y) of the point. Then each point is transformed into a 3 dimnesional hidden space of (h1, h2, h3) axis data (and hence the three neurons, which is then brought back into the 2 dimensional (orange, blue) axis space. The transformation from inputs to hidden dimensions is caused by a weight matrix whose dimensions would be (2, 3) (2 dimensional data being transformed into 3 dimensional data).
This transformation is the root of all matrix algebra and vector algebra
Also, the process of finding the right weight matrices, a.k.a., back-propagation is another genius trick that we could talk some other time
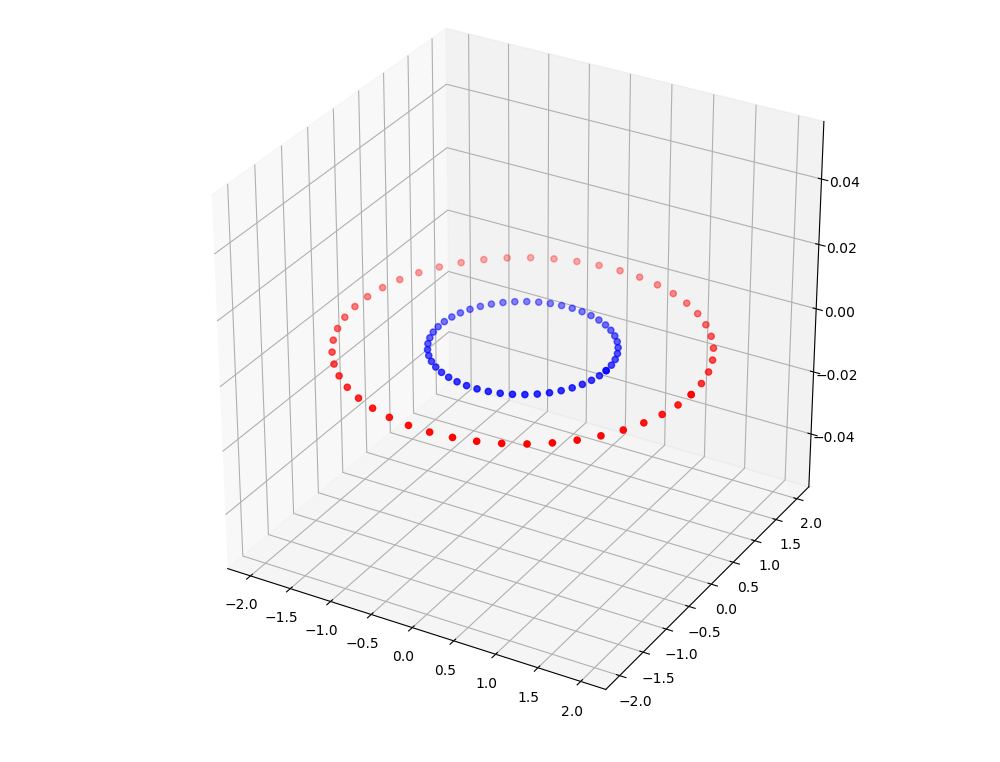
Initially for the machine all the data is simply there on the ground. Just lying. No redness or blueness attached. It knows nothing, like John Snow.
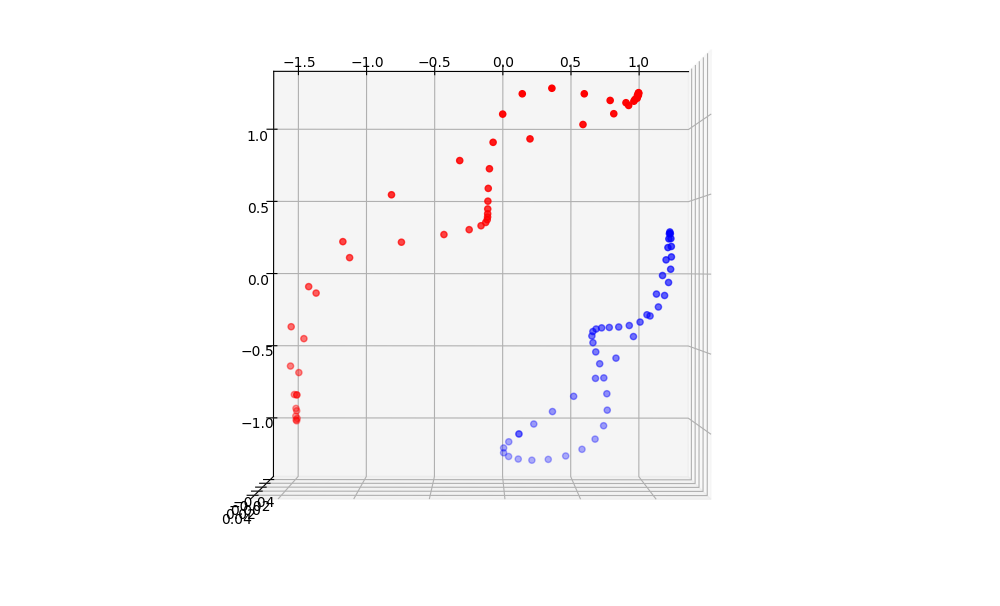
But after the first transformation, the points are shot into 3d space.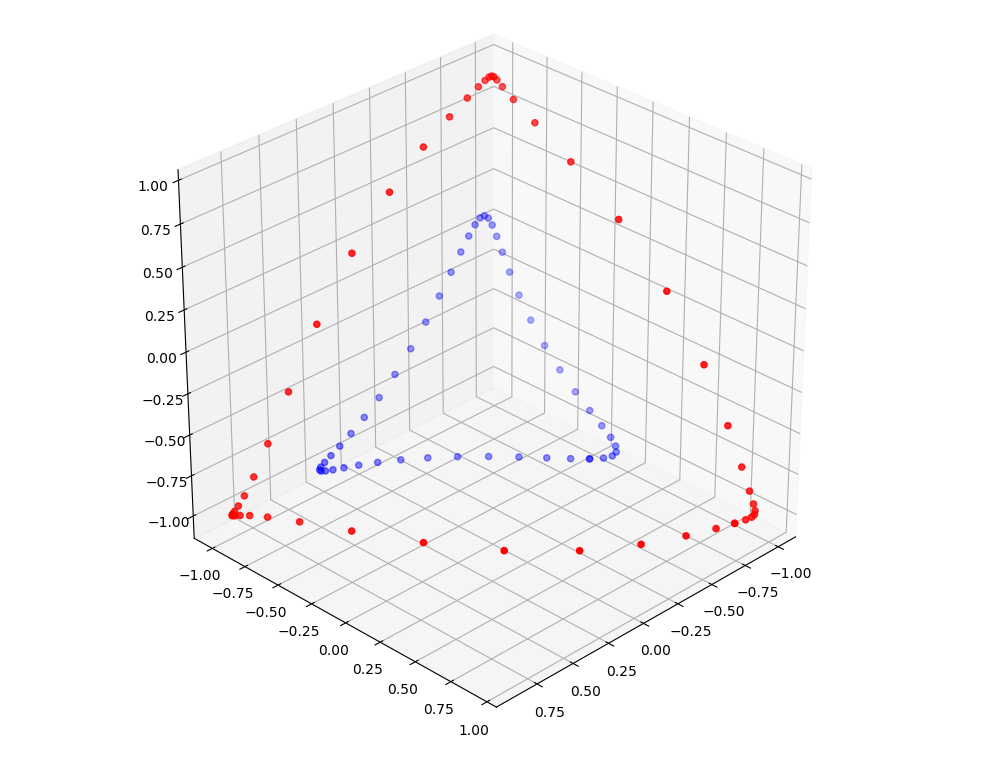
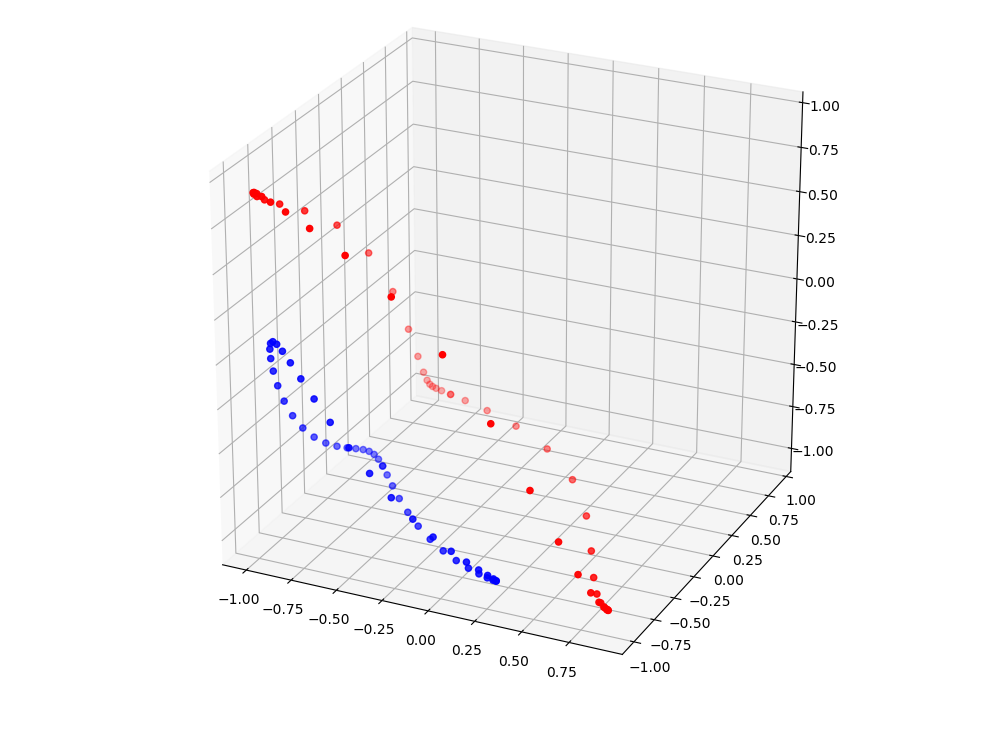
You can already see how the two circles are two triangles in 3D. From the second perspective it is clear that one could cut a slice of the cube with a slant plane and have the two triangles on two sides of it. Techincally we have made the data linearly separable.
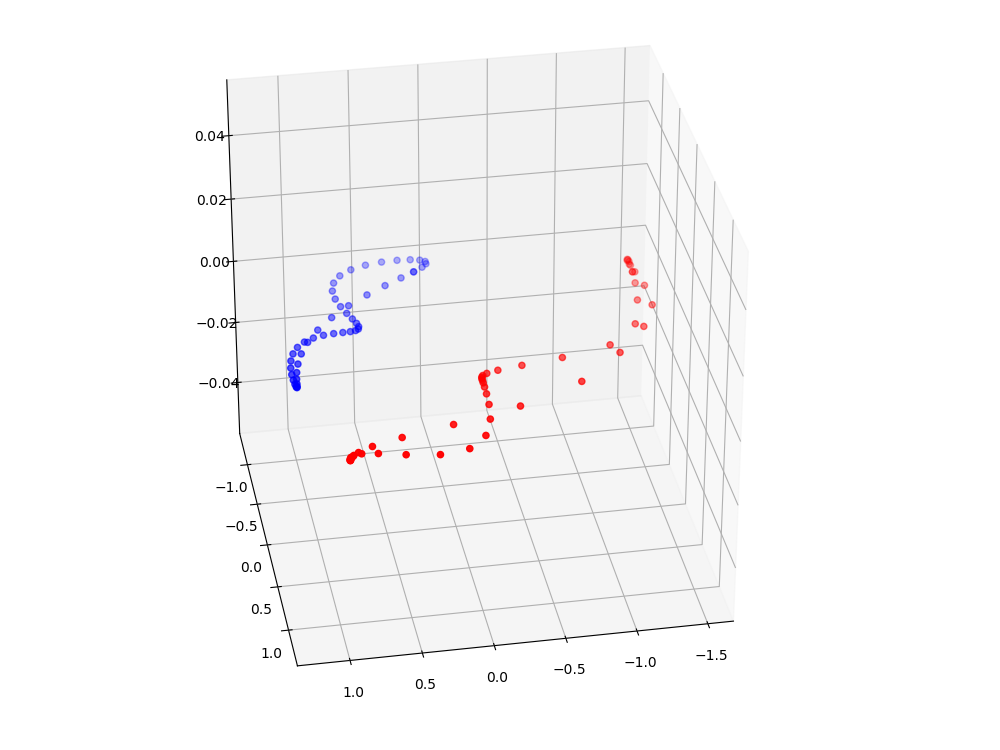
The second transformation is again bringing the data back into 2 dimensions. However the projection is from a different vantaget point such that the two clusters remain separate.
The softmax layer is a special transform which simply returns a 'yes'/'no' kind of output for every class. The last transformation looks like this
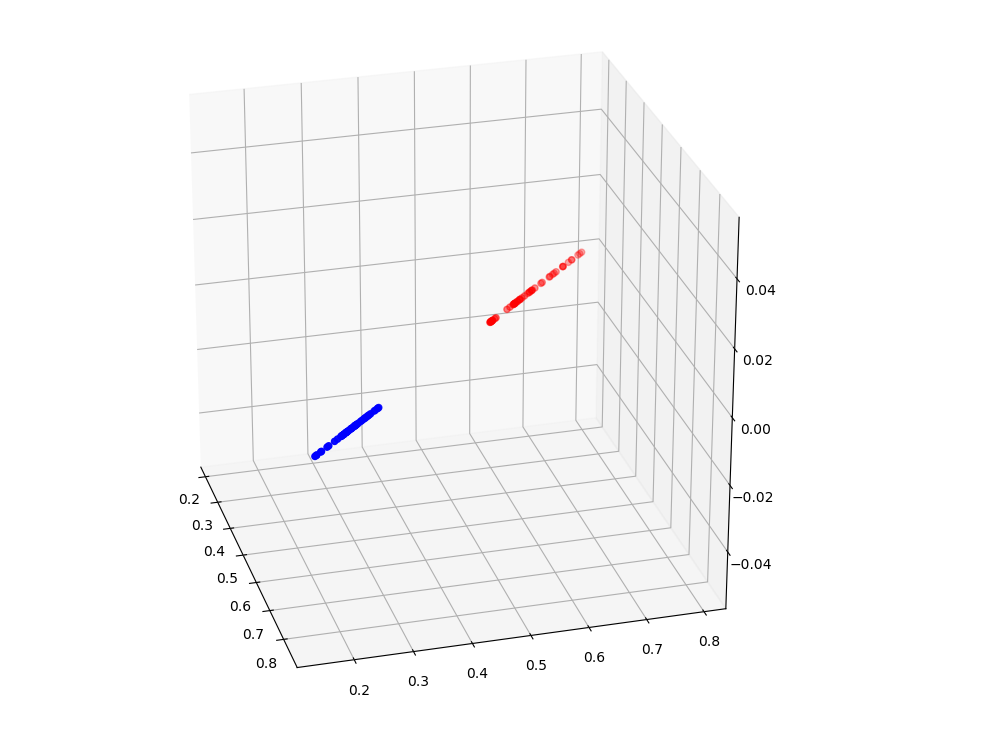
This process is exactly what we meant by the kernel trick. By saying neural networks can find their own kernels, we mean -
- it can take data into any higher/lower/same dimensions we specify.
- it can do that as many times as there are hidden layers.
- if it finds a right combination of these transforms (this is automaticallly done by back-propagation which is a topic for another day) the data becomes linearly separable.